


이지형 교수 연구실, LREC-COLING 2024 논문 2편 게재 승인
- 인공지능학과
- 조회수1269
- 2024-04-02

정보 및 지능 시스템 연구실(지도교수: 이지형)의 논문 2편이 자연어 처리 분야 저명한 국제 학술대회 LREC-COLING (BK IF=2) “The 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING ’24)”에 게재 승인되었습니다.
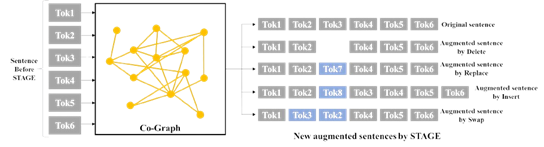
논문 #1: “STAGE: Simple Text Data Augmentation by Graph Exploration”, LREC-COLING 2024
(인공지능학과 박사과정 김호승, 인공지능학과 박사과정 강용훈)
"STAGE: Simple Text Data Augmentation by Graph Exploration" 논문에서는 텍스트 데이터를 그래프로 변환하고 이를 활용한 데이터 증강(Data Augmentation)하는 방법을 제안합니다. 기존 방법론은 복잡성, 비용, 그리고 성능에 대해서 조금 더 나은 해결방안이 필요 되어집니다. 우리의 STAGE(Simple Text Data Augmentation)는 공동 그래프(Co-graph)를 활용한 최적의 수정될 단어를 선택합니다. 수정된 단어를 Delete, replace, insert, swap 방법을 사용하여 문장을 증가시키는데, 이 방법은 기존보다 복잡함과 비용은 줄이고 더 나은 성능을 보입니다.
[Abstract] Pre-trained language models (PLMs) are widely used for various tasks, but fine-tuning them requires sufficient data. Data augmentation approaches have been proposed as alternatives, but they vary in complexity, cost, and performance. To address these challenges, we propose STAGE (Simple Text Data Augmentation by Graph Exploration), a highly effective method for data augmentation. STAGE utilizes simple modification operations such as insertions, deletions, replacements, and swaps. However, what distinguishes STAGE lies in the selection of optimal words for each modification. This is achieved by leveraging a word-relation graph called the co-graph. The co-graph takes into account both word frequency and co-occurrence, providing valuable information for operand selection. To assess the performance of STAGE, we conduct evaluations using seven representative datasets and three different PLMs. Our results demonstrate the effectiveness of STAGE across diverse data domains, varying data sizes, and different PLMs. Also, STAGE demonstrates superior performance when compared to previous methods that use simple modification operations or large language models like GPT3.
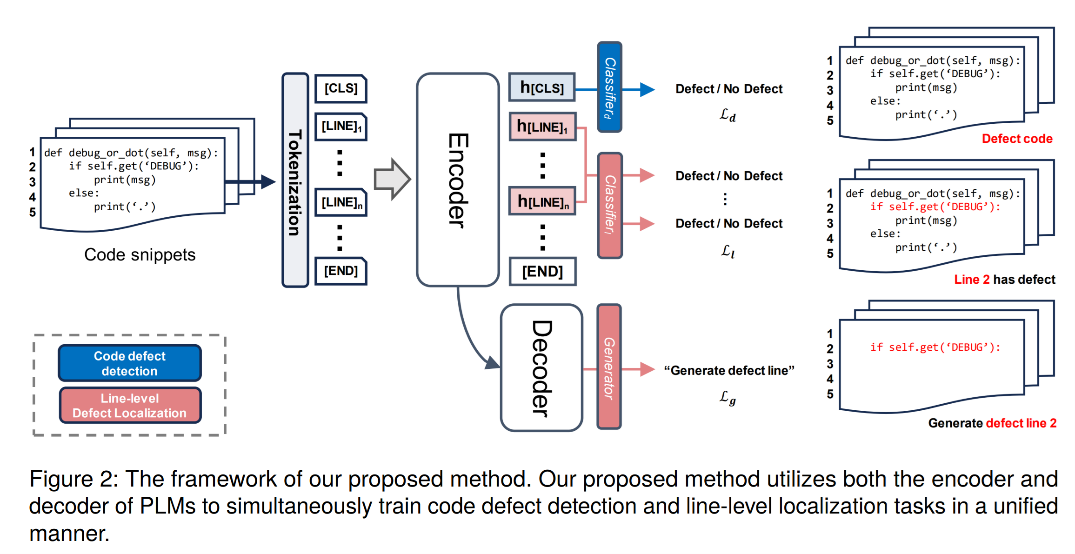
논문 #2: “Code Defect Detection using Pre-trained Language Models with Encoder-Decoder via Line-Level Defect Localization”, LREC-COLING 2024
(인공지능학과 석사과정 안지민*, 2024년 소프트웨어학과 박사 졸업 최윤석*(공동 1저자*))
(논문 #2)
“Code Defect Detection using Pre-trained Language Models with Encoder-Decoder via Line-Level Defect Localization” 논문에서는 코드에서의 결함 감지(Code Defect Detection) 작업을 효과적으로 수행하기 위해 코드의 라인 수준에서 결함을 식별하는 새로운 방법을 제안합니다. 라인 수준에서 결함을 식별하기 위해, 스페셜 토큰을 사용하여 코드를 라인으로 분리된 시퀀스로 변환합니다. 그런 다음, 사전학습모델(Pre-trained Models)의 인코더와 디코더가 정보를 다른 방식으로 처리하는 특성을 활용하여 라인 수준의 결함 지역화(defect localization)을 위해 인코더와 디코더를 모두 활용합니다. 코드 결함 검출 및 라인 수준의 결함 지역화를 통합하여 두 작업 간의 지식 공유(knowledge sharing)를 촉진하는 것이 제안 방법입니다. 실험 결과, 코드 결함 검출에 대한 네 가지 벤치마크 데이터 셋에서 성능을 크게 향상시키는 것을 확인해 제안방법이 효과적임을 보였습니다.
[Abstract] Recently, code Pre-trained Language Models (PLMs) trained on large amounts of code and comment, have shown great success in code defect detection tasks. However, most PLMs simply treated the code as a single sequence and only used the encoder of PLMs to determine if there exist defects in the entire code. For a more analyzable and explainable approach, it is crucial to identify which lines contain defects. In this paper, we propose a novel method for code defect detection that integrates line-level defect localization into a unified training process. To identify code defects at the line-level, we convert the code into a sequence separated by lines using a special token. Then, to utilize the characteristic that both the encoder and decoder of PLMs process information differently, we leverage both the encoder and decoder for line-level defect localization. By learning code defect detection and line-level defect localization tasks in a unified manner, our proposed method promotes knowledge sharing between the two tasks. We demonstrate that our proposed method significantly improves performance on four benchmark datasets for code defect detection. Additionally, we show that our method can be easily integrated with ChatGPT.