허재필 교수 연구실, AAAI 2024 논문 4편 게재 승인
- 인공지능학과
- 조회수1729
- 2023-12-14

비주얼컴퓨팅연구실 (지도교수: 허재필)의 논문 4편이 인공지능 분야의 우수 학술대회인 AAAI Conference on Artificial Intelligence 2024 (AAAI-24)에 게재 승인되었습니다.
논문 #1: “Towards Squeezing-Averse Virtual Try-On via Sequential Deformation”
(인공지능학과 박사과정 심상헌, 인공지능학과 석사과정 정지우)
논문 #2: "Noise-free Optimization in Early Training Steps for Image Super-Resolution"
(인공지능학과 박사과정 이민규)
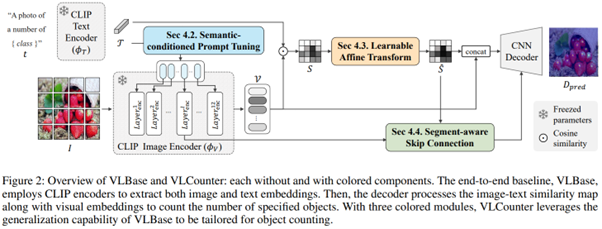
논문 #3: “VLCounter: Text-aware Visual Representation for Zero-Shot Object Counting”
(인공지능학과 석사과정 강승구, 인공지능학과 박사과정 문원준, 인공지능학과 석사졸업 김의연)
논문 #4: “Task-disruptive Background Suppression for Few-Shot Segmentation”
(소프트웨어학과/기계공학부 학사과정 박수호, 인공지능학과 박사과정 이수빈, 인공지능학과 박사과정 현상익, 인공지능학과 박사과정 성현석)
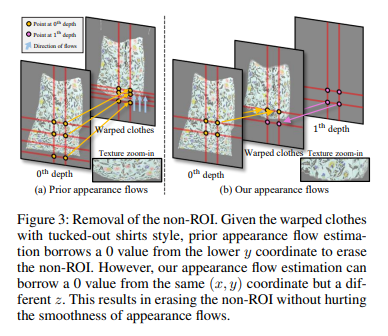
Towards Squeezing-Averse Virtual Try-On via Sequential Deformation" 논문에서는 고해상도 가상시착 영상생성 분야에서의 시각적 품질 저하 문제를 다루고 있습니다. 구체적으로, 그림 1(a)의 위쪽 행에서 볼 수 있듯이, 소매 부분에서 옷의 텍스쳐가 압착되는 문제가 있었습니다. 이 문제의 주요 원인은 해당 분야에서 필수적으로 사용되는 두 가지 손실 함수인 TV (Total Variation loss) 손실과 적대적 손실 (adversarial loss) 사이의 기울기 충돌 때문입니다. TV 손실은 와핑된 옷 마스크에서 소매와 몸통 사이의 경계를 분리하는 것을 목표로 하는 반면, 적대적 손실은 둘 사이의 결합을 목표로 합니다. 이러한 반대되는 목표는 잘못된 기울기를 계단식 외관 흐름 추정(Cascaded appearance flow estimation)으로 피드백하여 소매 압착 아티팩트를 발생시킵니다. 이를 해결하기 위해, 해당 논문에서는 네트워크의 레이어 간 연결의 관점으로 접근하였습니다. 구체적으로, 기존 계단식 외관 흐름 추정이 잔류 연결 (residual connection) 구조로 연결되어 적대적 손실 함수의 영향을 많이 받기 때문에 소매 압착이 발생한다고 진단하였고, 이를 줄이기 위해 계단식 외관 흐름 간의 순차적 연결 (sequential connection) 구조를 네트워크의 마지막 레이어에 도입하였습니다. 한편, 그림 1(a)의 아래쪽 행은 허리 주변의 다른 유형의 압착 아티팩트를 보여줍니다. 이를 해결하기 위해, 본 연구에서는 옷을 와핑할 때, 우선 내어 입는 스타일 (tucked-out shirts style)로 와핑한 후, 초기 와핑 결과에서 텍스쳐를 부분적으로 삭제할 것을 제안하고 이를 위한 연산을 구현하였습니다. 제안된 기술은 두 유형의 아티팩트를 성공적으로 해결하는 것을 확인하였습니다.
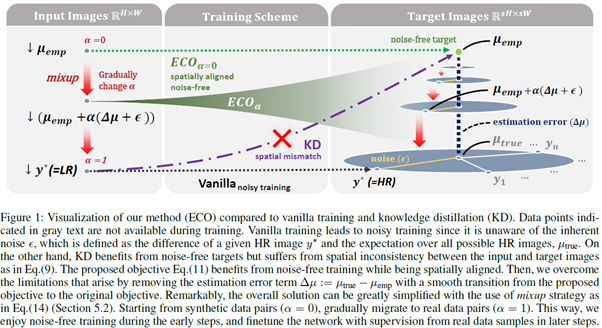
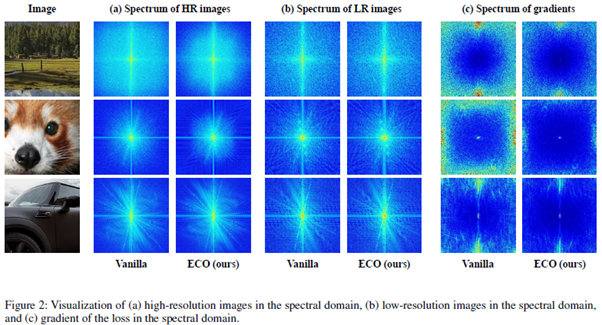
“Noise-free Optimization in Early Training Steps for Image Super-Resolution” 논문에서는 이미지 초해상화 문제에서의 기존 학습 방법론과 지식 전이(Knowledge Distillation)의 한계점을 다루고 있습니다. 구체적으로, 하나의 고해상도 이미지를 두 개의 핵심 요소인 최적 평균(optimal centroid)과 잠재 노이즈(inherent noise)로 분리 및 분석했습니다. 이를 통해, 학습 데이터의 잠재 노이즈가 초반 학습의 불안정성을 유도하는 것을 확인했습니다. 해당 문제를 해결하기 위해, Mixup 기술과 기학습된 네트워크를 활용하여 학습 과정에서 잠재 노이즈를 제거하여 보다 안정적인 학습 기술을 제안했습니다. 제안된 기술은 Fidelity-oriented single image super-resolution 분야에서 여러 모델에 걸쳐 일관된 성능 향상을 가져오는것을 확인했습니다.
"VLCounter: Text-aware Visual Representation for Zero-Shot Object Counting" 논문에서는 이미지에서 텍스트로 지정된 객체의 개수를 세는 문제를 다루고 있습니다. 해당 논문은 선행 연구의 two-stage 방법은 방대한 연산량과 에러 전파의 가능성이라는 문제를 제기하였습니다. 앞선 문제의 해결을 위해 one-stage baseline인 VLBase와 세 주요 기술로 확장된 VLCounter를 제안합니다. 첫째로, 기학습된 거대 모델인 CLIP을 재학습하는 대신 Visual Prompt Tuning(VPT)을 도입하였습니다. 추가로, VPT의 학습 가능한 토큰에 텍스트 정보를 추가하여 해당하는 개체가 강조된 이미지 피쳐를 얻게 합니다. 둘째로, 객체 영역의 전체가 아닌 중요한 부분만을 강조하는 유사도 맵을 얻기 위해 미세 조정이 이루어졌습니다. 이로써 모델은 객체 중심의 활성화를 높일 수 있습니다. 셋째로, 모델의 일반화 능력 향상과 정확한 객체 위치 파악을 위해 이미지 인코더 피쳐를 디코딩에 통합하고 앞선 유사도 맵을 피쳐에 곱하여 객체 영역에 집중합니다. 제안된 기술은 기존 방법의 성능을 크게 상회할 뿐만 아니라, 가벼운 모델로 학습 및 추론 속도를 2배 향상시켰습니다.
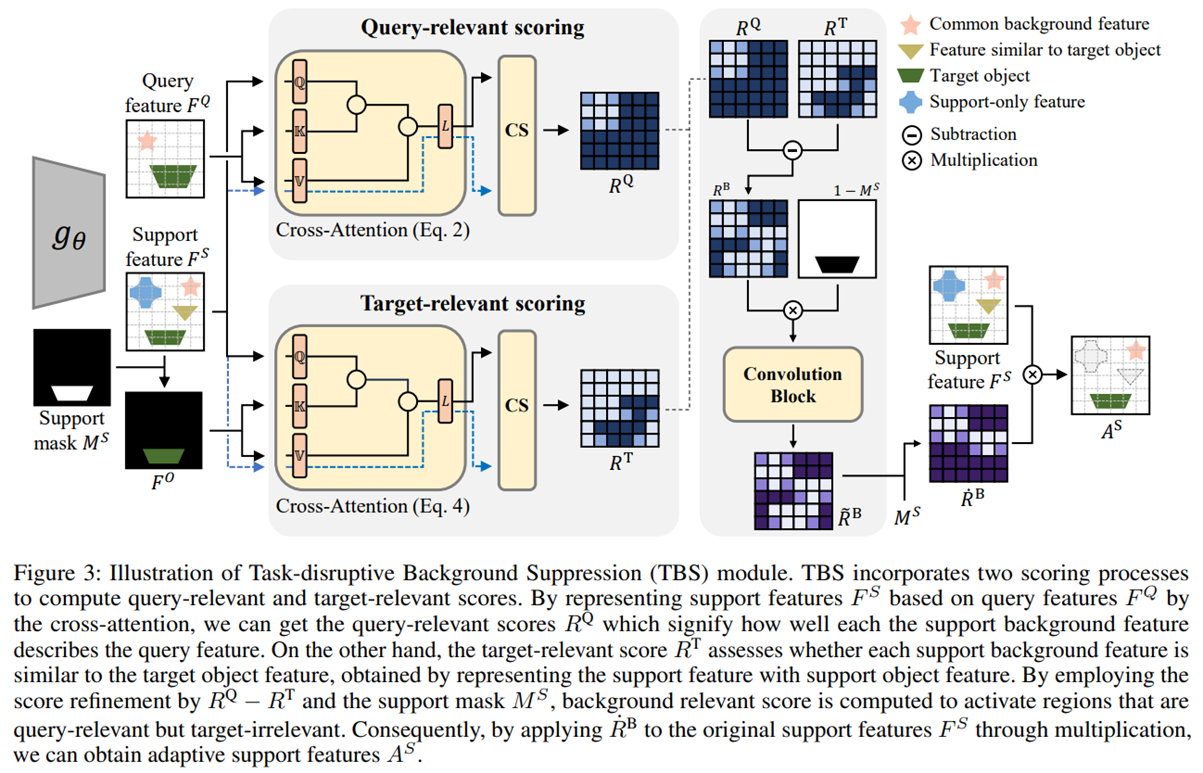
“Task-disruptive Background Suppression for Few-shot Segmentation” 논문에서는 적은 수의 이미지(Support)와 마스크를 참고하여 새로운 이미지(Query)안의 물체를 찾아내는 few-shot segmentation문제에서 Support의 배경을 효율적으로 다루기 위한 방법을 다루고 있습니다. 기존 모델에서는 segmentation을 하기 위해서 Support와 Query를 비교하는데, 각각의 배경을 비교할 경우 다음과 같은 문제점이 있습니다. 첫번째로, Support와 Query의 배경이 많이 다를 경우 이는 모델이 segmentation을 하는데 방해가 될 수 있습니다. 두번째로, Support의 배경에 segmentation하고자 하는 물체와 비슷한 물체가 있는 경우도 방해가 될 수 있습니다. 따라서 본 논문은 방해가 될 수 있는 이 두 가지 배경의 요소를 Query-relevant score와 Target-relevant score를 통해 제거하였습니다. 따라서 결과적으로 Query의 배경과 관련된 Support의 배경만 남도록 하여 Support의 배경을 더욱 효율적으로 참고하도록 하였습니다. 제안된 방법은 여러 Few-shot Segmentation 모델에서 성능 향상이 있는 것을 확인했습니다.
[논문 #1 정보]
Towards Squeezing-Averse Virtual Try-On via Sequential Deformation
Sang-Heon Shim, Jiwoo Chung, and Jae-Pil Heo
Thirty-Eighth AAAI Conference on Artificial Intelligence (AAAI), 2024
Abstract:
In this paper, we first investigate a visual quality degradation problem observed in recent high-resolution virtual try-on approach. The tendency is empirically found that the textures of clothes are squeezed at the sleeve, as visualized in the upper row of Fig.1(a). A main reason for the issue arises from a gradient conflict between two popular losses, the Total Variation (TV) and adversarial losses. Specifically, the TV loss aims to disconnect boundaries between the sleeve and torso in a warped clothing mask, whereas the adversarial loss aims to combine between them. Such contrary objectives feedback the misaligned gradients to a cascaded appearance flow estimation, resulting in undesirable squeezing artifacts. To reduce this, we propose a Sequential Deformation (SD-VITON) that disentangles the appearance flow prediction layers into TV objective-dominant (TVOB) layers and a task-coexistence (TACO) layer. Specifically, we coarsely fit the clothes onto a human body via the TVOB layers, and then keep on refining via the TACO layer. In addition, the bottom row of Fig.1(a) shows a different type of squeezing artifacts around the waist. To address it, we further propose that we first warp the clothes into a tucked-out shirts style, and then partially erase the texture from the warped clothes without hurting the smoothness of the appearance flows. Experimental results show that our SD-VITON successfully resolves both types of artifacts and outperforms the baseline methods.

[논문 #2 정보]
Noise-free Optimization in Early Training Steps for Image Super-Resolution
MinKyu Lee and Jae-Pil Heo
Thirty-Eighth AAAI Conference on Artificial Intelligence (AAAI), 2024
Abstract:
Recent deep-learning-based single image super-resolution (SISR) methods have shown impressive performance whereas typical methods train their networks by minimizing the pixel-wise distance with respect to a given high-resolution (HR) image. However, despite the basic training scheme being the predominant choice, its use in the context of ill-posed inverse problems has not been thoroughly investigated. In this work, we aim to provide a better comprehension of the underlying constituent by decomposing target HR images into two subcomponents: (1) the optimal centroid which is the expectation over multiple potential HR images, and (2) the inherent noise defined as the residual between the HR image and the centroid. Our findings show that the current training scheme cannot capture the ill-posed nature of SISR and becomes vulnerable to the inherent noise term, especially during early training steps. To tackle this issue, we propose a novel optimization method that can effectively remove the inherent noise term in the early steps of vanilla training by estimating the optimal centroid and directly optimizing toward the estimation. Experimental results show that the proposed method can effectively enhance the stability of vanilla training, leading to overall performance gain.
[논문 #3 정보]
VLCounter: Text-aware Visual Representation for Zero-Shot Object Counting
Seunggu Kang, WonJun Moon, Euiyeon Kim, and Jae-Pil Heo
Thirty-Eighth AAAI Conference on Artificial Intelligence (AAAI), 2024
Abstract
Zero-Shot Object Counting (ZSOC) aims to count referred instances of arbitrary classes in a query image without human-annotated exemplars. To deal with ZSOC, preceding studies proposed a two-stage pipeline: discovering exemplars and counting. However, there remains a challenge of vulnerability to error propagation of the sequentially designed two-stage process. In this work, we propose an one-stage baseline, Visual-Language Baseline (VLBase), exploring the implicit association of the semantic-patch embeddings of CLIP. Subsequently, we extend the VLBase to Visual-language Counter (VLCounter) by incorporating three modules devised to tailor VLBase for object counting. First, we introduce Semantic-conditioned Prompt Tuning (SPT) within the image encoder to acquire target-highlighted representations. Second, Learnable Affine Transformation (LAT) is employed to translate the semantic-patch similarity map to be appropriate for the counting task. Lastly, we transfer the layer-wisely encoded features to the decoder through Segment-aware Skip Connection (SaSC) to keep the generalization capability for unseen classes. Through extensive experiments on FSC147, CARPK, and PUCPR+, we demonstrate the benefits of our end-to-end framework, VLCounter.
[논문 #4 정보]
Task-disruptive Background Suppression for Few-Shot Segmentation
Suho Park, SuBeen Lee, Sangeek Hyun, Hyun Seok Seong, and Jae-Pil Heo
Thirty-Eighth AAAI Conference on Artificial Intelligence (AAAI), 2024
Abstract
Few-shot segmentation aims to accurately segment novel target objects within query images using only a limited number of annotated support images. The recent works exploit support background as well as its foreground to precisely compute the dense correlations between query and support. However, they overlook the characteristics of the background that generally contains various types of objects. In this paper, we highlight this characteristic of background which can bring problematic cases as follows: (1) when the query and support backgrounds are dissimilar and (2) when objects in the support background are similar to the target object in the query. Without any consideration of the above cases, adopting the entire support background leads to a misprediction of the query foreground as background. To address this issue, we propose Task-disruptive Background Suppression (TBS), a module to suppress those disruptive support background features based on two spatial-wise scores: query-relevant and target-relevant scores. The former aims to mitigate the impact of unshared features solely existing in the support background, while the latter is to reduce the influence of target-similar support background features. Based on these two scores, we define a query background relevant score which captures the similarity between the backgrounds of the query and the support, and utilize it to scale support background features to adaptively restrict the impact of disruptive support backgrounds. Our proposed method achieves state-of-the-art performance on PASCAL and COCO datasets on 1-shot segmentation.