데이터 지능 및 학습 연구실(지도교수: 이종욱), SIGIR 2022 및 IJCAI 2022 논문 게재
- 인공지능학과
- 조회수1830
- 2022-08-01
연구 1: Jae-woong Lee, Seongmin Park, Joonseok Lee, and Jongwuk Lee, “Bilateral Self-unbiased Learning from Biased Implicit Feedback”, 45th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR), 2022
연구 2: Duhyeon Bang, Kyungjune Baek, Jiwoo Kim, Yunho Jeon, Jin-Hwa Kim, Jiwon Kim, Jongwuk Lee, and Hyunjung Shim, “Logit Mixing Training for More Reliable and Accurate Prediction”, 31st International Joint Conference on Artificial Intelligence (IJCAI), 2022
연구 1: 데이터 지능 및 학습(Data Intelligence and Learning, DIAL) 연구실 소속 이재웅(박사과정, 제1저자) 학생, 박성민(석·박통합과정, 제2저자) 학생, 이종욱(교신저자) 교수와 이준석(구글 리서치/서울대, 제3저자) 교수가 연구한 “Bilateral Self-unbiased Learning from Biased Implicit Feedback” 논문이 세계 최고 권위 정보검색 학회인 SIGIR 2022에 full paper track으로 최종 게재 승인되었으며, 지난 7월 12일 스페인 마드리드에서 논문을 발표하였습니다.

이재웅(박사과정) 박성민(석박통합과정)
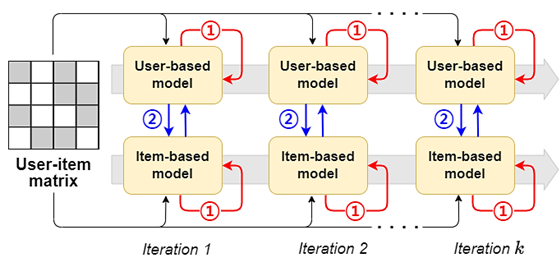
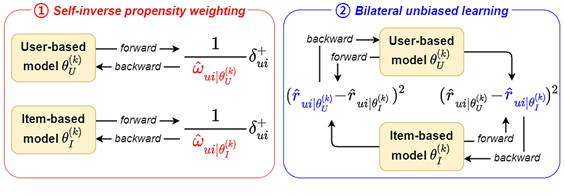
본 연구는 편향되어 있는 추천 데이터에서 추천 모델을 학습할 때 모델에 존재하는 편향 문제를 완화하는 추천 모델을 제안하였습니다. 구체적으로, 추천 데이터의 편향을 제거하기 위해 두 가지로 요소를 개발하여 추천 모델의 편향 제거에 활용하였습니다. (1) 모델의 출력에 포함되어 있는 편향으로 모델의 편향을 제거하는 자기 역편향 가중치(Self-inverse propensity weighting)를 통해 학습 과정에서 데이터의 편향을 완화하는 방법과 (2) 두 가지 상호 보완적인 추천 모델인 사용자기반 추천 모델과 항목기반 추천 모델을 활용하여 추천 모델의 편향을 안정적으로 제거하기 위해 예측 결과의 오차를 줄이는 방법인 양방향 편향 제거 학습(Bilateral unbiased learning)을 고안하였습니다. 제안된 추천 모델은 실험적으로 효과적으로 추천 결과의 편향을 제거됨을 확인하였으며, 편향 제거 평가 시 일반적으로 사용되는 Coat 및 Yahoo! R3 데이터에서 기존의 편향 제거 모델 대비 추천 성능을 최대 15% 개선하였습니다.
<그림 1: 사용자 기반 항목 기반 추천 모델을 활용하여 자기 역편향 가중치와 양방향 편향 제거 학습을 활용한 학습 과정>
연구 2: 데이터 지능 및 학습(Data Intelligence and Learning, DIAL) 연구실 소속 김지우(석사과정, 제3저자) 학생과 이종욱 교수와 카이스트 심현정 교수 연구팀이 공동 연구를 진행한 교수가 “Logit Mixing Training for More Reliable and Accurate Prediction” 논문이 세계 최고 권위 인공지능 학회인 IJCAI 2022에 full paper track으로 최종 게재 승인되었으며, 7월 23일에 연구 성과를 발표하였습니다.

김지우(석사과정)
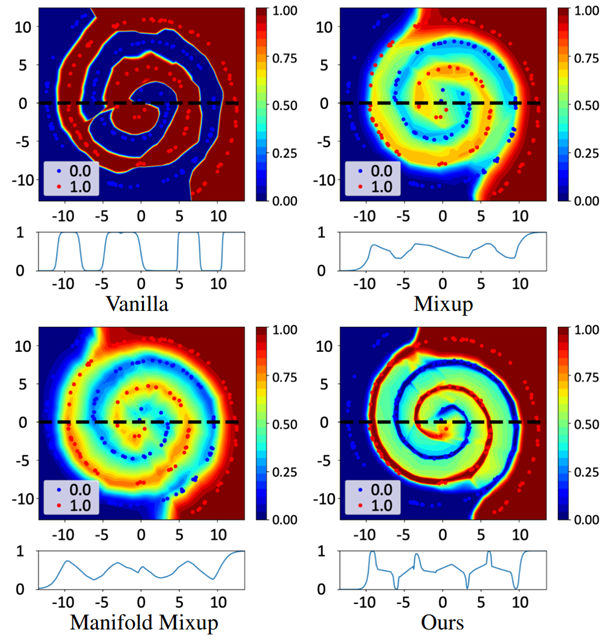
본 연구는 사람이 객관식 문제를 풀 때, 무엇이 정답인지를 고려할 뿐 아니라 무엇이 정답이 아닌지를 모두 고려하는 사람의 정답 추론 과정에 영감을 받아, 정답 클래스와 오답 클래스 간 관계를 모두 활용한 LogitMix를 제안하였습니다. 구체적으로, 본 연구에서 제안한 LogitMix는 기존에 데이터 증강 방법인 Mixup, Manifold Mixup, CutMix 및 PuzzleMix와 같은 방법과 결합이 가능하며, 두 데이터 결합 시 로짓(Logit) 레벨에서 두 샘플을 효과적으로 결합하는 방법입니다. 이를 통해, 긍정적(정답) 클래스와 부정적(오답) 클래스 간 관계를 보존하여, 효과적으로 클래스의 확률 분포를 학습 과정에 규제화하여 학습할 수 있도록 하였습니다. 제안 방법은 이미지 및 언어 기반 분류 모델에 효과적으로 LogitMix를 적용하여 교정 오류 및 예측 정확도를 개선할 수 있음을 검증하였습니다.
<그림: 2차원 나선형 데이에서 다양한 Mixup 기반의 학습 방법 적용시 분류 모델의 결정 평면에 대한 도식도, 제안 방법인 LogitMix가 다른 방법 대비 두 개의 클래스를 효과적으로 구분하고 있으며, 두 클래스간 확률 분포가 자연스럽게 변함을 확인됨>