


우사이먼 교수 연구실 IJCAI 2023 논문 게재 승인
- 인공지능학과
- 조회수1543
- 2023-05-03

DASH 연구실 (지도교수: 우사이먼) 김정호 (2023년 인공지능학과 석사 졸업), 이한빈 (2022년 인공지능학과 석사 졸업)의 “IMF: Integrating Matched Features using Attentive Logit in Knowledge Distillation” 논문이 인공지능 분야 최우수 학회 (BK IF=4) International Joint Conferences on Artificial Intelligence (IJCAI) 2023 에 게재 승인되어 8월에 발표될 예정입니다.
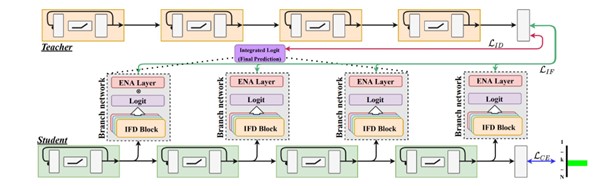
지식 증류(Knowledge distillation, KD)는 교사 모델의 지식을 학생 모델에 전달하여, 학생 모델의 성능을 향상시키는 방법이다. 소프트맥스 분포 및 네트워크 중간 특징 매칭 기반 지식 증류 방법은 다양한 작업에서 성능 향상을 보였지만, 학생 모델의 제한된 모델 용량으로 인해 일부분의 성능 개선만 가능하다. 본 연구에서는 학생 모델의 한계를 해결하기 위해 새로운 유연한 지식 증류 프레임워크, Attentive logit을 사용한 Integrating Matched Feature (IMF)를 제안한다. 본 방법은 중간 특징 증류기(IFD)를 도입하여 교사 모델의 지식을 직접 학생 모델의 가지 네트워크로 증류함으로써 학생 모델의 전반적인 성능을 향상시킨다. 여러 가지 네트워크는 Attentive Logit에 의해 선생 모델의 직접적인 증류하에 효과적으로 결합된다. 본 방법은 학생 모델의 일부 블록과 IFD를 사용하여 본래의 학생 네트워크와 동일하거나 적은 수의 파라미터로 추론하며, 다양한 데이터셋에서 다른 최신 방법론들보다 동일한 파라미터 및 연산량 하에 높은 성능 향상을 보인다.
Knowledge distillation (KD) is an effective method for transferring the knowledge of a teacher model to a student model, that aims to improve the latter's performance efficiently. Although generic knowledge distillation methods such as softmax representation distillation and intermediate feature matching have demonstrated improvements with various tasks, only marginal improvements are shown in student networks due to their limited model capacity. In this work, to address the student model's limitation, we propose a novel flexible KD framework, Integrating Matched Features using Attentive Logit in Knowledge Distillation (IMF). Our approach introduces an intermediate feature distiller (IFD) to improve the overall performance of the student model by directly distilling the teacher's knowledge into branches of student models. The generated output of IFD, which is trained by the teacher model, is effectively combined by attentive logit. We use only a few blocks of the student and the trained IFD during inference, requiring an equal or less number of parameters. Through extensive experiments, we demonstrate that IMF consistently outperforms other state-of-the-art methods with a large margin over the various datasets in different tasks without extra computation.