


우사이먼성일 교수 DASH 연구실, CIKM 2022 국제 학술대회 full paper 논문 5편 게재 승인
- 인공지능학과
- 조회수1651
- 2022-08-25
DASH 연구실 신유진, 박은주, 이광한, 이한빈, 김정호, 신새별, Binh M. Le, Chingis Oinar의 논문 5편이 full paper가 인공지능 및 정보검색 분야의 top-tier 국제학술대회인 CIKM (Conference on Information and Knowledge Management) 2022에 최종 논문 게재가 승인되어 10월에 발표될 예정입니다.
- 1. 항공우주연구원과 시계열 기반 괘도 예측 및 이상탐지 연구
- 2. Neural Networks Pruning 연구
- 3. 미국 USC와 YouTube의 콘텐츠 Privacy 및 유해성 관련 탐지 모델 개발 연구(국제공동)
- 4. 호주 CSIRO Data61과 시계열 데이터에 대한 Adversarial Attack 연구(국제공동)
- 5. Self-Knowledge Distillation기법을 제안하여 다양한 downstream 비전 테스크 성능향상 연구
1. Youjin Shin, Eun-Ju Park, Simon S. Woo, Okchul Jung and Daewon Chung, ”Selective Tensorized Multi-layer LSTM for Orbit Prediction”, Proceedings of the 31st ACM International Conference on Information & Knowledge Management. 2022.
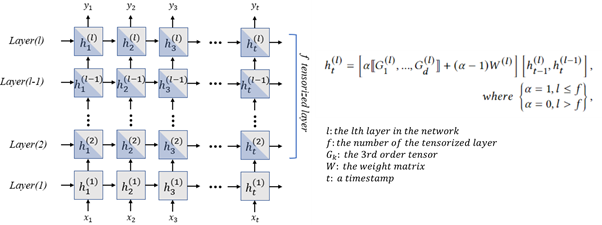
본 연구에서는 위성의 궤도를 예측하는 모델로서 Selective Tensorized multi-layer LSTM (ST-LSTM)을 제안합니다. 최근, 위성의 수가 급격하게 늘어남에따라 위성 충돌 위험이 증가하였습니다. 이러한 위성 충돌과 같은 돌발상황을 막기 위해서는 위성의 궤도를 정확하게 예측하는 것이 중요합니다. ST-LSTM은 딥러닝의 웨이트 매트릭스를 텐서화한 tensorizing layer를 멀티레이어 LSTM에 선택적으로 적용합니다. 항공우주연구소 (KARI)에서 제공된 두 개의 실제 위성에 대한 데이터를 가지고 다양한 비교 모델들과 함께 실험한 결과, ST-LSTM은 계산량을 줄이면서도 정확도 또한 높게 유지하였습니다.
Although the collision of space objects not only incurs a high cost but also threatens human life, the risk of collision between satellites has increased, as the number of satellites has rapidly grown due to the significant interests in many space applications. However, it is not trivial to monitor the behavior of the satellite in real-time since the communication between the ground station and spacecraft are dynamic and sparse, and there is an increased latency due to the long distance. Accordingly, it is strongly required to predict the orbit of a satellite to prevent unexpected contingencies such as a collision. Therefore, the real-time monitoring and accurate orbit prediction is required. Furthermore, it is necessarily to compress the prediction model, while achieving a high prediction performance in order to be deployable in the real systems. Although several machine learning and deep learning-based prediction approaches have been studied to address such issues, most of them have applied only basic machine learning models for orbit prediction without considering the size, running time, and complexity of the prediction model. In this research, we propose Selective Tensorized multi-layer LSTM (ST-LSTM) for orbit prediction, which not only improves the orbit prediction performance but also compresses the size of the model that can be applied in practical deployable scenarios. To evaluate our model, we use the real orbit dataset collected from the Korea Multi-Purpose Satellites (KOMPSAT-3 and KOMPSAT-3A) of the Korea Aerospace Research Institute (KARI) for 5 years. In addition, we compare our ST-LSTM to other machine learning-based regression models, LSTM, and basic tensorized LSTM models with regard to the prediction performance, model compression rate, and running time.
2. Gwanghan Lee, Saebyeol Shin, and Simon S. Woo, ”Accelerating CNN via Dynamic Pattern‑based Pruning Network”, Proceedings of the 31st ACM International Conference on Information & Knowledge Management. 2022.
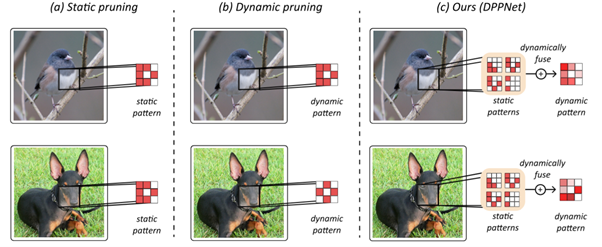
본 연구에서는 실제 가속이 가능한 dynamic pruning method를 제안합니다. 기존의 dynamic pruning method는 매 인풋샘플마다 sparse pattern이 다르기에, 가속을 위해 수행되는 추가적인 오버헤드때문에 실제 가속까지 이루어지기 어려웠습니다. 본 논문에서는 이를 해결하기 위해 새로운 dynamic pruning method를 제안하며, convolution kernel의 representational power를 높여 성능을 높였을 뿐만 아니라 BLAS 라이브러리를 이용해 쉽게 가속이 이루어질 수 있게 만들었습니다. 이를 통해 CIFAR과 ImageNet 데이터셋에서 실험한 결과 기존의 SOTA 방법론에 비해 연산량 대비 정확도가 향상됨을 보였습니다.
Most dynamic pruning methods fail to achieve actual acceleration due to the extra overheads caused by indexing and weight-copying to implement the dynamic sparse patterns for every input sample. To address this issue, we propose Dynamic Pattern-based Pruning Network, which preserves the advantages of both static and dynamic networks. Unlike previous dynamic pruning methods, our novel method dynamically fuses static kernel patterns, enhancing the kernel's representational power without additional overhead. Moreover, our dynamic sparse pattern enables an efficient process using BLAS libraries, accomplishing actual acceleration. We demonstrate the effectiveness of the proposed network on CIFAR and ImageNet, outperforming the state-of-the-art methods achieving better accuracy with lower computational cost.
3. Binh M. Le, Rajat Tandon, Chingis Oinar, Jeffrey Liu, Uma Durairaj, Jiani Guo, Spencer Zahabizadeh, Sanjana Ilango, Jeremy Tang, Fred Morstatter, Simon Woo and Jelena Mirkovic, ”Samba: Identifying Inappropriate Videos for Young Children on YouTube”, Proceedings of the 31st ACM International Conference on Information & Knowledge Management. 2022.
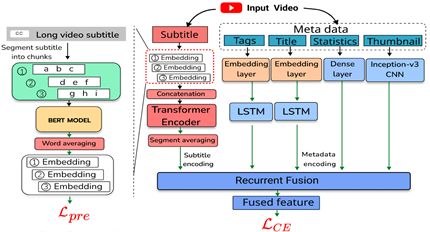
본 논문에서는 어린이용 유튜브 동영상을 분류하기위해 메타데이터와 비디오 자막을 모두 사용하는 Samba라는 퓨전 모델을 제안합니다. 기존 연구는 어린이들이 보기에 부적절한 비디오를 감지하기 위해 비디오 썸네일, 제목, 댓글 등과 같은 메타데이터를 활용했습니다. 이러한 메타데이터 기반 접근법은 높은 정확도를 달성하지만, 입력 feature의 신빙성으로 인해 상당한 오분류 결과를 가집니다. Self-supervised contrastive 프레임워크로 pre-train된, 자막에서의 representation feature를 추가함으로써, Samba 모델은 다른 SOTA 분류기보다 7% 이상 높은 성능을 보입니다. 또한 향후 연구를 장려하기 위해 7만여개의 영상도 함께 공개합니다.
In this paper, we propose a fusion model, called Samba, which uses both metadata and video subtitles for content classifying YouTube videos for kids. Previous studies utilized metadata, such as video thumbnails, title, comments, ect., for detecting inappropriate videos for young viewers. Such metadata-based approaches achieve high accuracy but still have significant misclassifications due to the reliability of input features. By adding representation features from subtitles, which are pretrained with a self-supervised contrastive framework, our Samba model can outperform other state-of-the-art classifiers by at least 7%. We also publish a large-scale, comprehensive dataset of 70K videos for future studies.
4. Shahroz Tariq, Binh M. Le and Simon Woo, ”Towards an Awareness of Time Series Anomaly Detection Models' Adversarial Vulnerability”, Proceedings of the 31st ACM International Conference on Information & Knowledge Management. 2022.
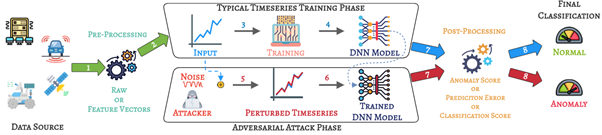
본 연구에서는 시계열 데이터의 이상(anomaly) 검출기의 적대적 취약성에 대한 인식을 높이는 것을 목표로 하여, 센서 데이터에 약간의 적대적 섭동(adversarial perturbation)을 추가함에도 이상 감지 시스템이 심각하게 약화되는 것을 보입니다. 이상 현상(anomaly)에 대해 견고하며 실제 시스템에서 사용될 수 있다고 주장하는 SOTA 심층 신경망(DNN)과 그래프 신경망(GNN)의 성능이 FGSM(Fast Gradient Sign Method)과 PGD(Projected Gradient Descent)와 같이 잘 알려진 적대적 공격에서 0%로 떨어진다는 것을 보입니다. 우리가 아는 한, 본 연구는 적대적 공격에 대한 이상 감지 시스템의 취약성을 처음으로 입증하였습니다.
Time series anomaly detection is studied in statistics, ecology, and computer science. Numerous time series anomaly detection strategies have been presented utilizing deep learning. Many of these methods exhibit state-of-the-art performance on benchmark datasets, giving the false impression that they are robust and deployable in a wide variety of real-world scenarios. In this study, we demonstrate that adding modest adversarial perturbations to sensor data severely weakens anomaly detection systems. Under well-known adversarial attacks such as Fast Gradient Sign Method (FGSM) and Projected Gradient Descent (PGD), we demonstrate that the performance of state-of-the-art deep neural networks (DNNs) and graph neural networks (GNNs), which claim to be robust against anomalies and possibly be used in real-world systems, drops to 0%. We demonstrate for the first time, to our knowledge, the vulnerability of anomaly detection systems to adversarial attacks. This study aims to increase awareness of the adversarial vulnerabilities of time series anomaly detectors.
5. Hanbeen Lee, Jeongho Kim and Simon Woo, “Sliding Cross Entropy for Self-Knowledge Distillation”, Proceedings of the 31st ACM International Conference on Information & Knowledge Management. 2022.
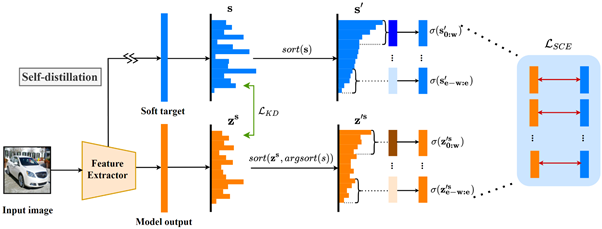
본 연구에서는 기존 self-knowledge distillation에 결합하여 성능을 향상시키는 Sliding Cross Entropy (SCE)를 제안합니다. Self-distillation을 위한 soft target과 모델의 output logit의 차이를 최소화하기 위하여, 정렬된 각 softmax representation을 특정 윈도우로 나누고, 나누어진 슬라이스끼리의 거리를 최소화합니다. 이를 통하여, 모델은 최적화 과정에서 soft target의 클래스간 관계를 동등하게 고려할 수 있습니다. 다양한 실험을 통하여 본 논문에서 제안하는 SCE가 분류, 객체 탐지, 세그멘테이션에서 기존 베이스라인 방법론을 뛰어넘는 성능을 보여줍니다.
Knowledge distillation (KD) is a powerful technique for improving the performance of a small model by leveraging the knowledge of a larger model. Despite its remarkable performance boost, KD has a drawback with the substantial computational cost of pre-training larger models in advance. Recently, a method called self-knowledge distillation has emerged to improve the model's performance without any supervision. In this paper, we present a novel plug-in approach called Sliding Cross Entropy (SCE) method, which can be combined with existing self-knowledge distillation to significantly improve the performance. Specifically, to minimize the difference between the output of the model and the soft target obtained by self-distillation, we split each softmax representation by a certain window size, and reduce the distance between sliced parts. Through this approach, the model evenly considers all the inter-class relationships of a soft target during optimization. The extensive experiments show that our approach is effective in various tasks, including classification, object detection, and semantic segmentation. We also demonstrate SCE consistently outperforms existing baseline methods.